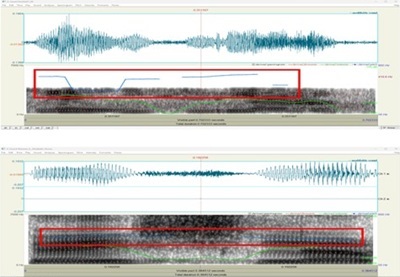
Pitch contour comparison illustrating stable modulation in the authentic voice versus erratic, elevated modulation in the disputed voice, a hallmark of synthetic or manipulated audio. Credit: Fernando Fernández
by Fernando Fernández and Lyanne L. Flores Báez
The rapid advancement of artificial intelligence has transformed the forensic landscape, introducing both new tools and new threats. In the realm of audio evidence, voice cloning and AI-generated speech have blurred the line between truth and fabrication. In courtrooms around the world, digital recordings are increasingly presented as key pieces of evidence—yet few are subjected to the rigorous forensic validation required to confirm their authenticity.
In early 2025, a case in Puerto Rico presented such a challenge. A short voice recording, lasting barely seventy-six seconds, was introduced as critical evidence in an ongoing judicial proceeding. The audio appeared simple at first: a phone call involving three individuals, containing the repeated utterance of a single name. However, beneath the surface of the waveform lay inconsistencies that raised significant questions about its integrity.
As the appointed forensic team, our objective was not to interpret the content of the recording, but to scientifically determine whether the voice attributed to one of the participants was genuine—or a digital imitation. What began as a routine voice comparison evolved into a full-scale investigation into the manipulation of sound, digital artifacts, and the potential use of artificial intelligence to fabricate a person’s voice.
This case illustrates a pivotal moment in modern forensic science: when the ability to detect manipulation becomes as crucial as the ability to analyze speech itself. Through this analysis, we sought to uncover the hidden truth within the sound—where every frequency, formant, and fragment of silence could reveal whether a human or a machine was speaking.
Case context and objective
The recording under examination was submitted to the forensic laboratory by the court in February 2025 under the filename “500 Avenida Los Filtros 3.m4a.” The file, just over one minute in duration, was reportedly captured during a phone conversation involving multiple speakers. From the moment of its reception, the case carried a significant weight: the authenticity of the audio could directly influence the credibility of the parties involved and the trajectory of the legal process.
The initial review identified several technical limitations. The M4A format, native to Apple devices, is not ideal for forensic analysis because it employs compression that restricts the visibility of subtle acoustic patterns. To ensure lossless processing, the file was converted to WAV using Audacity 3.7.1, a step that preserved the original integrity of the waveform and allowed full compatibility with Praat 6.4.27, the software used for acoustic and phonetic analysis.
Upon conversion, the waveform was visually inspected for irregularities—sudden amplitude drops, waveform discontinuities, and digital noise spikes. Two isolated fragments immediately stood out: each contained the spoken name “Keishla.” These segments, labeled Keishla01.wav and Keishla02.wav, would later become the cornerstone of the forensic comparison. Both samples appeared acoustically clean, yet their tonal structure and spectral envelope diverged sharply from what would be expected in a natural conversation.
To perform a scientific comparison, three controlled reference recordings (indubitable samples) were obtained from the individual alleged to be speaking in the disputed clip. These samples were recorded using a Neumann TLM102 condenser microphone and a Universal Audio Apollo Twin Mkll interface in a sound-treated environment. Each sample contained the subject pronouncing the same keyword—Keishla—to ensure direct comparability.
The primary objective of this forensic report was two-fold:
1) Authenticity Analysis: Determine whether the digital file exhibited evidence of editing, manipulation, or artificial generation.
2) Speaker Verification: Evaluate whether the voice in the disputed samples corresponded acoustically and phonetically to the known speaker.
What followed was a meticulous process of forensic dissection, where every pitch contour, formant resonance, and microsecond of silence was scrutinized. In this examination, the science of sound became a language through which truth could be measured—not by words, but by frequencies.
Forensic methodology
Forensic audio analysis operates at the intersection of acoustics, physics, and digital technology. Each frequency within a voice carries measurable identifiers—its fundamental pitch, the harmonic structure, and the resonant formants shaped by the vocal tract. To evaluate whether a recording has been manipulated or artificially generated, analysts must isolate these parameters and compare them with known samples under controlled conditions.
The audio file titled ‘500 Avenida los Filtros 3’ was loaded into the Audacity interface for conversion. Credit: Fernando Fernández
The examination began with the preprocessing of the received file. After converting 500 Avenida Los Filtros 3.m4a to the uncompressed WAV format, the waveform was segmented into discrete regions corresponding to the two utterances of the name “Keishla.” These fragments, labeled Keishla01 and Keishla02, were exported independently to preserve their integrity and analyzed separately from the complete recording.
Parallel to this, three authenticated voice samples from the alleged speaker were recorded. Each indubitable sample was captured under standardized laboratory conditions using a Neumann TLM102 microphone and a Universal Audio Apollo Twin mkII interface, connected to a MacBook Pro forensic workstation. These devices ensured high-fidelity digital acquisition and reproducible acoustic parameters.
The analytical process comprised several stages:
- Spectral Visualization: The spectrogram—a time-frequency map—was generated for each sample to identify anomalies such as abrupt energy discontinuities, missing harmonic bands, or irregular noise floors that suggest splicing or synthesis.
- Pitch (F0) Analysis: Conducted in Praat 6.4.27 to determine the fundamental frequency of each voice sample. Pitch serves as the primary metric for vocal identity and modulation stability.
- Formant (F1–F3) Extraction: Resonant frequencies that define the unique shape of a person’s vocal tract. Differences in formant positioning across vowels provide strong indicators of non-human or mismatched voices.
- Digital Artifact Inspection: Using Audacity’s waveform view, micro-level clicks, glitches, and static bursts were located and timestamped for further analysis, as these often indicate abrupt editing or digital reproduction.
To eliminate environmental bias, a frequency filter (300–3500 Hz) was applied in Praat, isolating the range typical of human speech while excluding background artifacts. This process enhanced the clarity of both genuine and dubious samples, enabling precise visual and numerical comparison.
Each result was documented in accordance with SWGDE best practices for digital media evidence, ensuring reproducibility and chain-of-custody integrity. The following section presents the analytical findings derived from these examinations—where frequencies revealed the first tangible signs that the voice in question might not have belonged to a human speaker.
Acoustic and spectral findings
The acoustic fingerprint of a human voice is rarely static—it fluctuates naturally as we breathe, emphasize words, or express emotion. When such organic variation is absent, the waveform begins to reveal its artificial origin. The comparative analysis between the indubitable and disputed recordings exposed precisely that kind of anomaly: a pattern of acoustic perfection that, paradoxically, betrayed its inauthenticity.
Pitch (F0) analysis
The three indubitable recordings from the reference speaker displayed a stable pitch range between 227 Hz and 253 Hz, consistent with natural female vocal frequencies. The tone was steady, with minor oscillations typical of spontaneous human speech.
By contrast, the disputed samples (Keishla01 and Keishla02) exhibited pitch frequencies between 336 Hz and 384 Hz—significantly higher and punctuated by abrupt modulations inconsistent with normal vocal behavior. These sharp frequency jumps suggest algorithmic reconstruction rather than biological phonation. In forensic terms, such discontinuities indicate that the waveform may have been synthetically generated or heavily altered through pitch manipulation software.
Formant resonance (F1–F3)
When analyzing vowel resonance, the discrepancies became more conclusive. In the reference samples, F2 for the vowels “e” and “i” ranged between 2100 Hz and 2460 Hz, and F3 consistently exceeded 2750 Hz, forming a clear spectral pattern typical of human vocal articulation. In the disputed recordings, F2 values dropped drastically—1140 Hz for “e” and 1220 Hz for “i”—while F3 fell below 2300 Hz. These values are incompatible with a natural vocal tract. In AI-synthesized speech, the algorithm replicates the timbre of a voice but fails to reproduce the biomechanical resonances of the human mouth and nasal cavities. This mismatch was clearly visible in the spectrographic formant map.
Absence of respiration and natural inflection
Further anomalies surfaced in the temporal structure of the waveform. In both disputed utterances, there were no inhalation or exhalation traces before or after the spoken words—an impossibility in real human speech, especially when calling out a name. The absence of breath sounds, coupled with a flat intonation lacking urgency or emotional contour, strongly indicated a prerecorded or artificially generated voice devoid of physiological dynamics.
Spectral artifacts and discontinuities
Several non-human signatures were also detected: click artifacts at time marks 04.38s, 05.00s, and 26.16s; static bursts (notably at 05.47s) consistent with glitches in digital reproduction, not telephony; and call-waiting tones from a device unassociated with the primary signal path—suggesting the overlay of pre-existing audio onto another conversation.
Together, these anomalies painted a coherent forensic picture: the recording was not a seamless capture of a real-time call, but a composite audio, assembled through insertions, cuts, and likely AI-assisted voice synthesis. The human ear might overlook these inconsistencies, but the spectrogram does not lie. In the digital realm, every truth leaves a frequency.
Interpretation and discussion
Forensic audio analysis extends beyond numbers and graphs—it is the scientific interpretation of how and why a sound exists. Each irregularity, each missing breath, and each harmonic fracture contributes to reconstructing the chain of events that produced (or fabricated) a recording. In this case, the synthesis of evidence pointed to a single, undeniable conclusion: the disputed voice could not have originated from a natural, continuous act of human speech.
The divergence between the indubitable and disputed samples was too substantial to attribute to environmental or equipment variation. Formant displacement, pitch instability, and spectral discontinuity all aligned with characteristics typical of AI-generated or heavily edited audio. In particular, the low F2 and F3 frequencies and the unnaturally high pitch indicate the absence of genuine vocal tract resonance—something only possible when a voice is computationally reconstructed rather than physically produced.
Moreover, the absence of natural breathing intervals and emotional inflection is consistent with machine-synthesized output. A human voice, even in controlled or low-volume speech, exhibits micro-pauses and airflow transitions between phrases. The analyzed recordings lacked these entirely. Instead, they presented an acoustic “sterility”—a digital stillness often found in synthetic speech where emotional dynamics are mathematically flattened.
Implications for judicial proceedings
From a legal standpoint, these findings carry profound implications. In judicial contexts, the admissibility of digital audio depends on its authenticity and the ability to establish an unbroken chain of custody. Once manipulation or synthesis is detected, the evidentiary weight of such material collapses.
The presence of playback clicks, and call-waiting tones also demonstrated that portions of the recording originated from a device other than the one claimed. This contradiction undermines the continuity of the event and invalidates the premise of a live, unedited call. Such discrepancies must be flagged to prevent the introduction of tampered evidence in court—a responsibility that falls directly on forensic experts.
The human factor in digital truth
Artificial intelligence can imitate human tone, but not human intent. While a cloned voice may replicate the acoustic timbre of a speaker, it cannot emulate the physiological or emotional nuances of real speech. The forensic task, therefore, is not only to identify technical inconsistencies but to interpret the behavior of sound: how it breathes, pauses, and reacts. In this case, the data revealed that what appeared to be a spontaneous conversation was, in reality, a digitally orchestrated illusion.
In the digital era, where deepfake voices can be generated in seconds, this case underscores the crucial role of certified forensic analysts in defending the boundary between truth and fabrication. The technology that creates deception must be met with the science that detects it.
Last thoughts
The forensic investigation of “500 Avenida Los Filtros 3” exposed a fundamental truth of the modern digital era: voices can be fabricated, but frequencies cannot lie. Through the systematic examination of pitch, formants, and spectral structure, it became evident that the disputed recording was not the product of a single, continuous human act. Instead, it bore the unmistakable acoustic fingerprints of editing, synthesis, and digital assembly.
Each technical anomaly—the abrupt pitch modulations, the missing respiration intervals, the displaced formants, and the digital artifacts—converged toward one consistent conclusion: the voice had been artificially generated or modified. In the courtroom, this distinction carries immense weight. What might sound plausible to an untrained ear can, under forensic scrutiny, unravel into a mosaic of computational fragments. Science exposes what perception cannot.
This case underscores an urgent reality for the global forensic community: the line between authentic and synthetic evidence is narrowing. As AI voice generation tools become increasingly accessible, so too must forensic protocols evolve to detect their misuse. The application of acoustic forensics, supported by standardized methodologies such as SWGDE and ASTM guidelines, provides the essential safeguard against digital deception.
Ultimately, the purpose of forensic science is not to confirm belief, but to uncover truth—objectively, transparently, and without prejudice. In this investigation, the data spoke clearly: what was presented as a human voice was, in fact, a digital echo of one.
About the authors
Fernando Fernández is a Board Accredited Investigator and Certified International Investigator with over two decades of experience in criminal, civil, and digital forensic investigations. As Chief Investigator at CIG, LLC, he is an internationally recognized Private Investigator and Forensic Expert in Digital Evidence and Artificial Intelligence. Fernández has been awarded internationally, receiving the 2025 Investigator of the Year Award by the World Association of Detectives and the 2024 Forensic Expert of the Year in Criminal Investigation by the Ilustre Colegio Nacional de Peritos of México.
Lyanne L. Flores Báez is a Certified Forensic Analyst specializing in audio and acoustic forensics, with expertise in the detection of manipulated recordings and voice cloning. She also holds a degree in Commercial Advertising and a degree in Music Production, along with a diploma in Forensic Acoustics and Phonetics from the Ilustre Colegio Nacional de Peritos de México. Flores Báez collaborates with CIG, LLC, conducting forensic audio examinations for judicial and investigative applications.